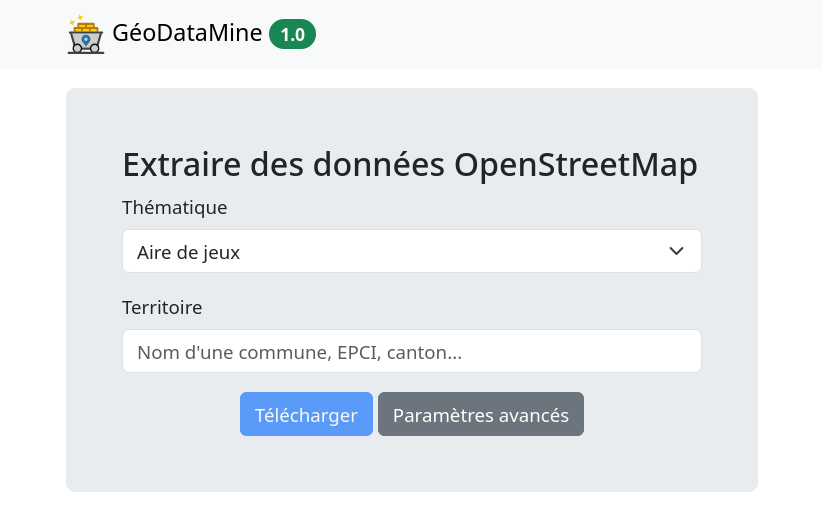
GéoDataMine s'offre une deuxième jeunesse
Aujourd’hui, petit partage d’un périple technique : la montée de version et la migration de GéoDataMine, l’outil dédié à l’extraction facilitée des données OpenStreetMap, notamment pour les collectivités territoriales. Migration qui se traduit par des performances accrues, une sécurité renforcée, et une meilleure adéquation avec les schémas de données nationaux les plus récents.

Retours du State of the Map Europe 2025
Les 14 et 15 novembre 2025, le State of the Map Europe s’est tenu à Dundee, en pleine Écosse. L’évènement regroupe la communauté OpenStreetMap Européenne sur 2 jours pour partager les nouveautés logicielles, les initiatives cartographiques, et adresser de nouveaux défis. J’ai eu la chance d’y participer : voici mes coups de cœur, découvertes, et les tendances qui vont marquer l’écosystème OSM dans les mois à venir.

Work with full-history OpenStreetMap files
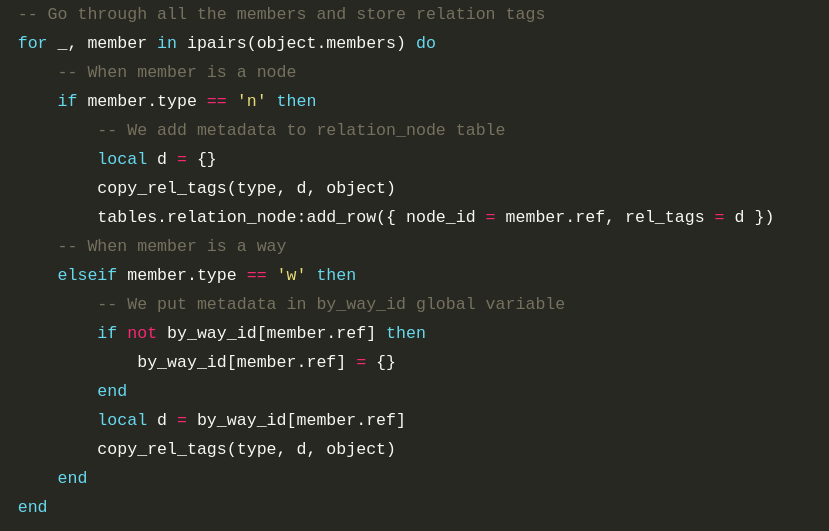
I’m working with a small team to develop ProjetDuMois.fr (project of the month) to encourage thematic contribution on OpenStreetMap during a month in France. This website will offer to community a dashboard with contribution statistics, a web map for efficient mapping, and badges for gamification. To offer precise and up-to-date statistics, it was necessary to start working with full-history OpenStreetMap files (.osh.pbf). It was a new topic to discover, and I will share with you this process journey, hoping to make it easier for others to work with these files.

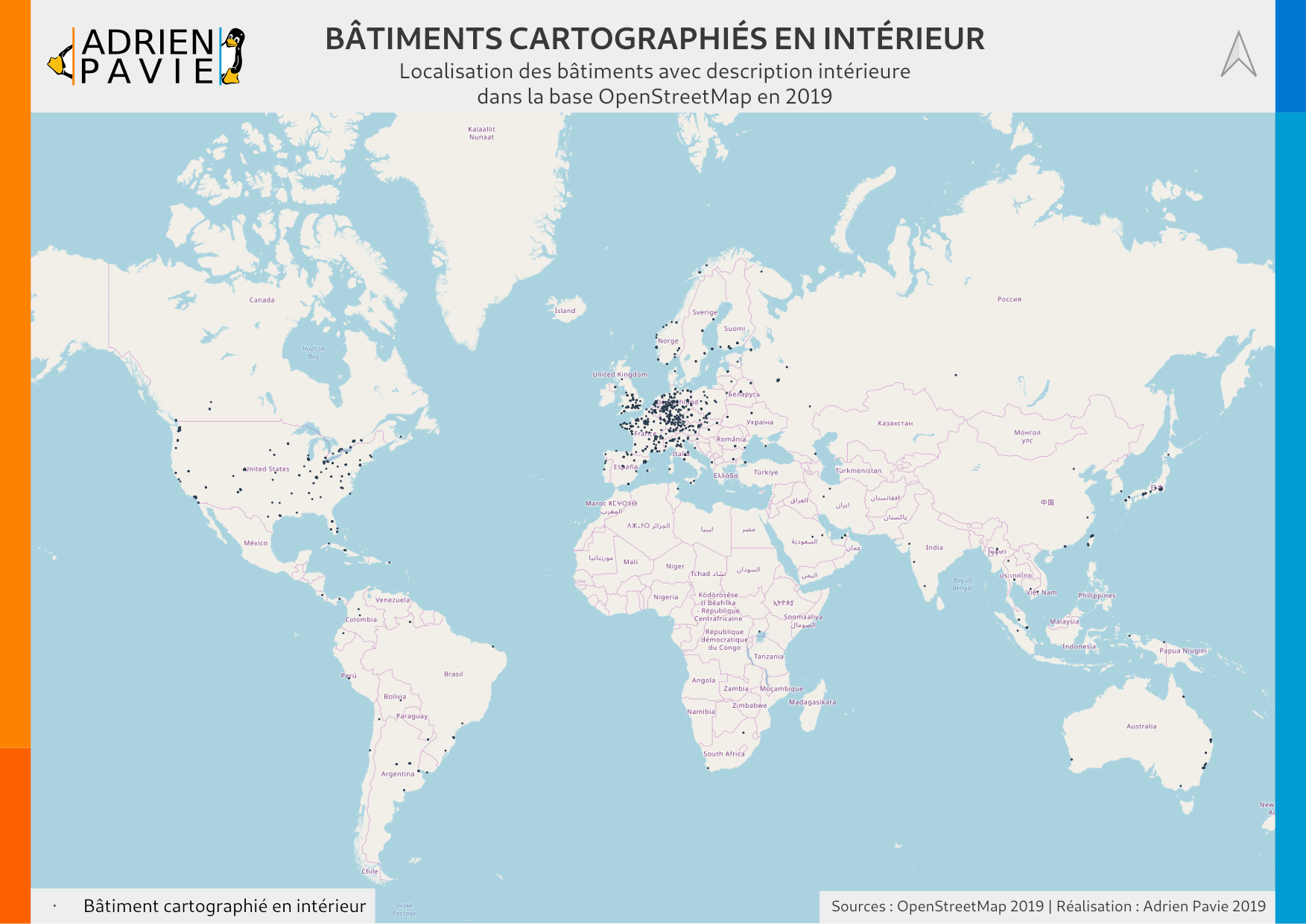
Où sont les lieux cartographiés en intérieur sur OpenStreetMap ?
La cartographie d’intérieur sur OpenStreetMap est un vaste sujet, présent depuis des années au sein de la communauté. Par cartographie d’intérieur, on entend le fait de détailler l’architecture d’un bâtiment, niveau par niveau de manière précise : pièces, couloirs, escaliers, et les activités qui se déroulent dans chacun de ces espaces. Cela est rendu possible par un ensemble d’attributs (schéma “Simple Indoor Tagging”) qui permettent d’indiquer sur chaque objet sa typologie (salle, espace, mur) et son étage (0 pour le rez-de-chaussée, 1 pour le 1er étage…).
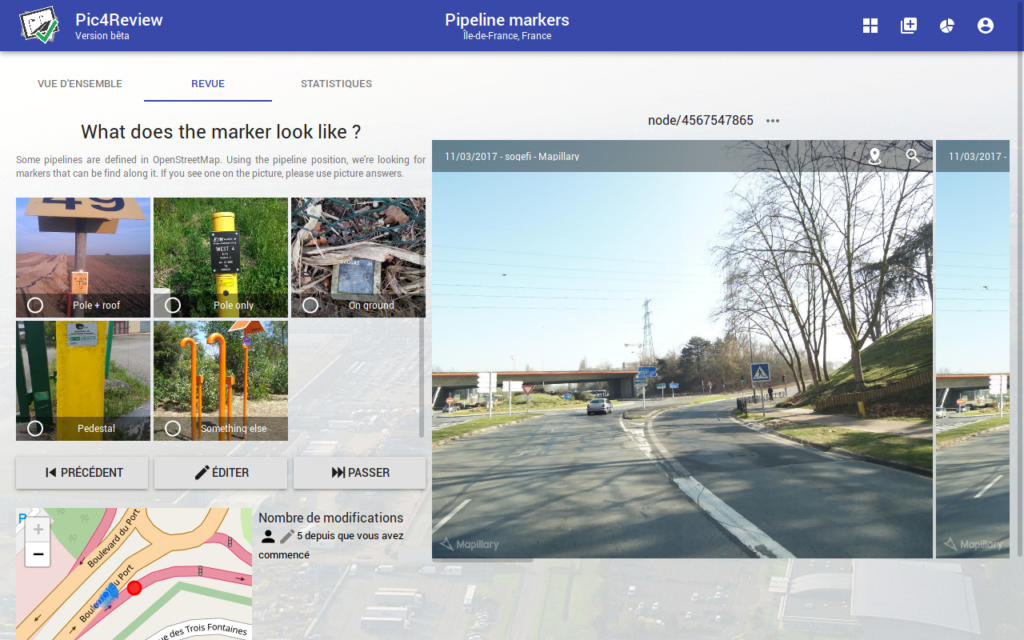
Pic4Review : photos de rues et données ouvertes
Pic4Review est un éditeur facilitant la contribution à la carte collaborative OpenStreetMap. Il propose de renseigner des informations sur des objets géolocalisés à partir de photos de rues libres de droits. Lancé fin 2017, il a permis à des centaines de contributeurs d’améliorer la description de centaines de milliers d’objets à travers le monde. Le principe est simple : vous participez à des missions thématiques sur une zone donnée, et pour chaque objet les photos disponibles sont présentées. Cela vous permet de répondre facilement à une question posée.