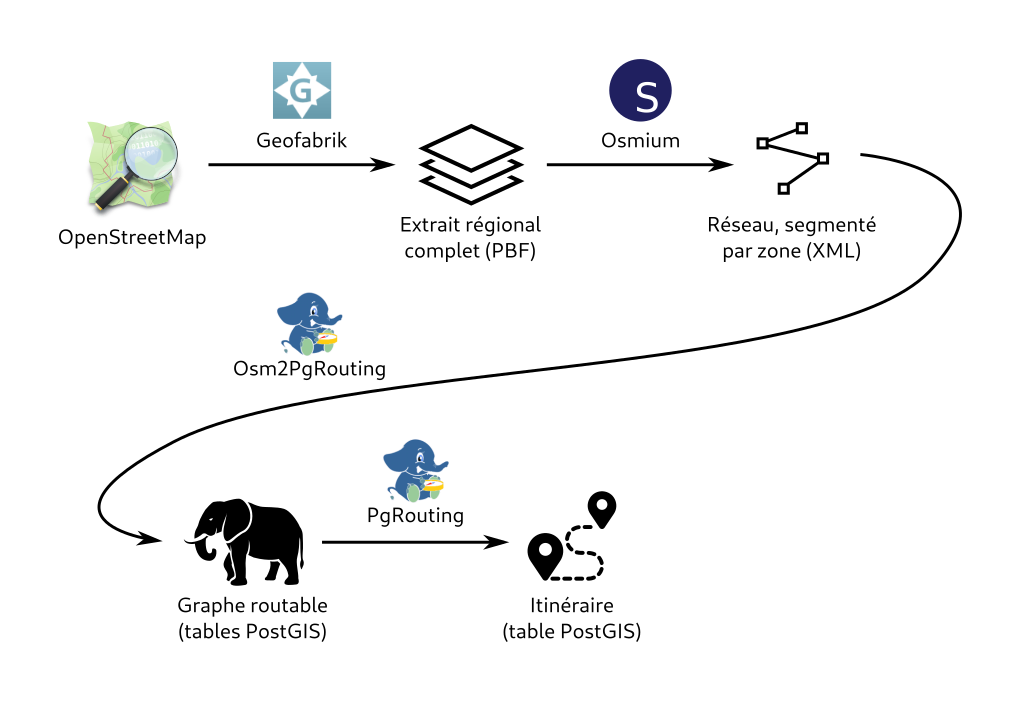
Osm2pgsql tool is quite famous in the OpenStreetMap community : it allows to transform raw OSM data into a ready-to-use PostgreSQL database. It is commonly used for setting up rendering or geocoding databases. People also use it to run various data analysis, which are made quite simple using extensions like PostGIS. However, for a quite long time, it was not so intuitive to fine tune osm2pgsql to go further. This is now past as Jochen Topf released a new « flex back-end » (still in experimental phase). This mode allows to configure how the database should look at the end of data process. In particular, you can process relations and copy tags they carry on other features like nodes or ways. Some documentation and examples are now available.
As I’m working on GeoDataMine (an easy-to-use OSM data extractor for local authorities), I was stuck on a very simple use case : getting street names from associatedStreet relations. In street numbers exports I was producing, street name were available when it was set as addr:street tag on nodes, but not when a node was a part of associatedStreet relation. This was frustrating : information exists, but you can’t access it. When Flex back-end was released, I was curious about if it allowed to solve this issue. TL;DR : it does ! Let’s get through my Flex journey.
Compiling osm2pgsql
First step is to make available latest osm2pgsql version available on your machine. If it is not (yet) available in your distribution repositories, you can compile it. Don’t be afraid, the process is quite straightforward. Just make sure you’re getting latest version (master branch of the Git repository).
Configuring Flex back-end
Next step is to create a Lua script to define what the database will look like after osm2pgsql import process. Some examples are available in the repository. I’m going for the compatible.lua file, as it mimics original back-end structure.
Columns
I want to have a rel_tags columns, similar to tags hstore but for storing all tags coming from relation. So, I just add a new column in my existing tables structure :
tables.point = osm2pgsql.define_table{ ... columns = { ... { column = 'tags', type = 'hstore' }, { column = 'rel_tags', type = 'hstore' }, { column = 'way', type = 'point' } } }
Note that this will work for addresses, as each node will only be part of one associatedStreet relation. If you’re working with bus lines for example, you will need a database structure handling features being part of several relations of same type.
Relation tags > node table
Creating your custom tables is a really interesting new feature in this Flex back-end. Here, I will create a table to associate relation tags to a node ID. This can be done after other tables declaration :
tables.relation_node = osm2pgsql.define_relation_table( 'planet_osm_relation_node', -- The name of the table { { column = 'node_id', type = 'bigint' }, { column = 'rel_tags', type = 'hstore' } } -- List of supplementary columns )
We do this only for nodes, as ways will be processed using another mechanism.
Process stages for ways
Flex back-end offers to process ways and relations in two separate stages :
- Stage 1 : default initial processing. Each OSM object is reviewed, but you can only access information concerning directly this object. For a node its tags and coordinates, for a way its tags and list of nodes, for a relation its tags and list of members. So no way to get relation tags when reviewing a node or way. But you can mark here a feature as needing a second review, after every feature has already been seen.
- Stage 2 : marked features are viewed a second time. There, you can access global variables from your script where you have stored useful information. For example, for a way ID, all tags of relations it is a part of. You can then put these tags in the database for definitive storage. Note that features marking only works for ways and relations as now (that’s why I’m using the relation_node table above) !
So let’s use this system to store relation metadata in a global variable, then associate it to ways. First, we create an empty global variable (near the start of script) :
by_way_id = {}
Then, we set-up the two stages system in the way-processing function, near the start lines of this function :
-- Ways are processed in stage 2 to retrieve relation tags if osm2pgsql.stage == 1 then osm2pgsql.mark_way(object.id) return end
Everything put in this function after these lines will be executed only in stage 2. That’s where we will add the code to get relation metadata and store it into the rel_tags we created earlier. This can be done using these lines (to put before any :add_row call) :
-- If there is any data from relations, add it in local d = by_way_id[object.id] if d then object.rel_tags = d end
Everything is now ready for both nodes and ways.
Store in memory relations metadata
Now, we have to edit osm2pgsql.process_relation(object) function to define what we want to save in memory or in relation_node table. This will be done by looping through all members of each relation.
-- Go through all the members and store relation tags for _, member in ipairs(object.members) do -- When member is a node if member.type == 'n' then -- We add metadata to relation_node table local d = {} copy_rel_tags(type, d, object) tables.relation_node:add_row({ node_id = member.ref, rel_tags = d }) -- When member is a way elseif member.type == 'w' then -- We put metadata in by_way_id global variable if not by_way_id[member.ref] then by_way_id[member.ref] = {} end local d = by_way_id[member.ref] copy_rel_tags(type, d, object) end end -- Outside of the process_relation, you can make available -- the copy_rel_tags function, which is an helper to merge -- all tags coming from various relations function copy_rel_tags(rel_type, d, object) for k,v in pairs(object.tags) do if k ~= "type" then d[rel_type .. '_' .. k] = v end end end
So, we’re good : metadata is stored, ways processed in stage 2 will retrieve it. The complete Lua script is here (a bit different because less tags are used in my database compared to compatible.lua file). Let’s run osm2pgsql.
Launch osm2pgsql
Just run the osm2pgsql command using appropriate option to use Flex back-end :
osm2pgsql --create \ -H localhost -U postgres -P 5432 -d mydb \ --slim --drop \ --style "my_flex_rules.lua" \ --output=flex \ extract.osm.pbf
If you have Lua-related issues, they are most likely to be originating in your script. As I’m no Lua expert, I had to redo this several times before having the perfectly-working script. Once done, your database is ready to explore.
Database final processing
Connect to your PostgreSQL database. You will see the four tables you defined. Check that each of them has data and its columns filled. For our street names use case, we’re not done yet ! In fact, ways have their rel_tags filled, but not nodes (point table). Let’s run a SQL request to fill rel_tags columns in point table :
UPDATE planet_osm_point SET rel_tags = a.rel_tags FROM ( -- Merge all tags for a certain node SELECT node_id, array_to_string(array_agg(rel_tags),',')::hstore AS rel_tags FROM planet_osm_relation_node GROUP BY node_id ) a WHERE a.node_id = osm_id; DROP TABLE planet_osm_relation_node;
At this point, you have your rel_tags columns filled everywhere. So now, we can get street names from both nodes and relations tag. For example :
SELECT osm_id, "addr:housenumber", -- Take first not null value COALESCE(rel_tags->'associatedStreet_name', tags->'addr:street') AS street FROM planet_osm_point WHERE "addr:housenumber" IS NOT NULL;
Quite handy, right ?
Conclusion
I’m really glad the osm2pgsql development team has released this new feature. Even if Lua is not the programming language I use the most, it’s still relatively easy to create your own configuration file. The given examples are really useful, I hope more will be released in the future to cover more use cases. I was a bit disappointed by the two-stages system not being available for nodes, but it seems temporary and shown workaround works well. It will definitely make advanced reuses of OSM data easier for developers and data analysts. You should give it a try !
Looking for OpenStreetMap data expertise for your projects ? Contact me and let’s discuss !